I had a situation where my lora gateway was offline for ~2 months and was brought back online.
I noticed the devices that were active on that gateway did not come back online (these are Elsys ERS motion sensors).
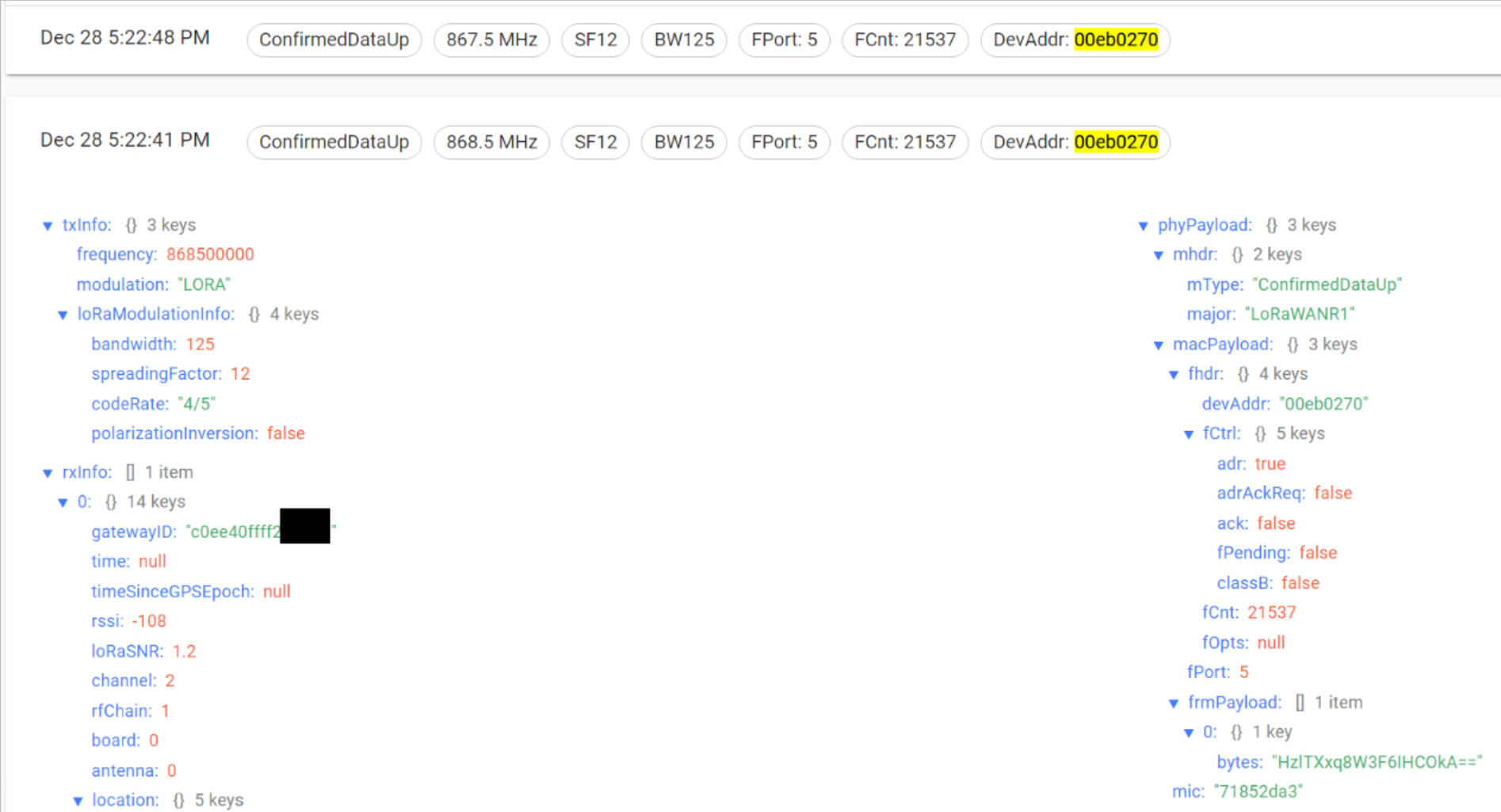
From viewing the uplinks coming from the back-online gateway I noticed that the devaddr of a device doing ConfirmedDataUp is the same as one in the device_activation table on chirpstack_ns postgres server. This leads me to think that the device is not configured to try to rejoin on not receiving downlinks.
How do devices lose the Activation on the chirpstack application server? Is it based on time?
Can I reinstate the existing activation and get the data flowing as expected?
The device-session (holding the snapshot of the all the device configuration at that moment) is held in Redis. The expiration is triggered by the configured device_session_ttl config option (default 31 days).
we also have Elsys ERS sensors. The big problem with these is, that by default, there is no timeout mechanism active which would force the sensor to retry a JOIN after not being able to communicate with any network server for a long time. I’d rather have devices always try to JOIN again just in case the encryption keys disappear to /dev/null etc. Redis is not my idea of a “stable” data store.
Is it possible to re-build the “device-session” (the snapshot of all device configuration) onto Redis after the event of disappearance of the Redis backing store at /var/lib/redis ?
There are plenty of network keys, etc, in psql::chirpstack_as::device_keys table.