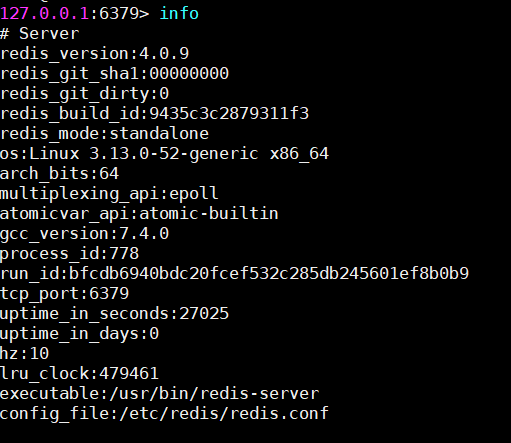
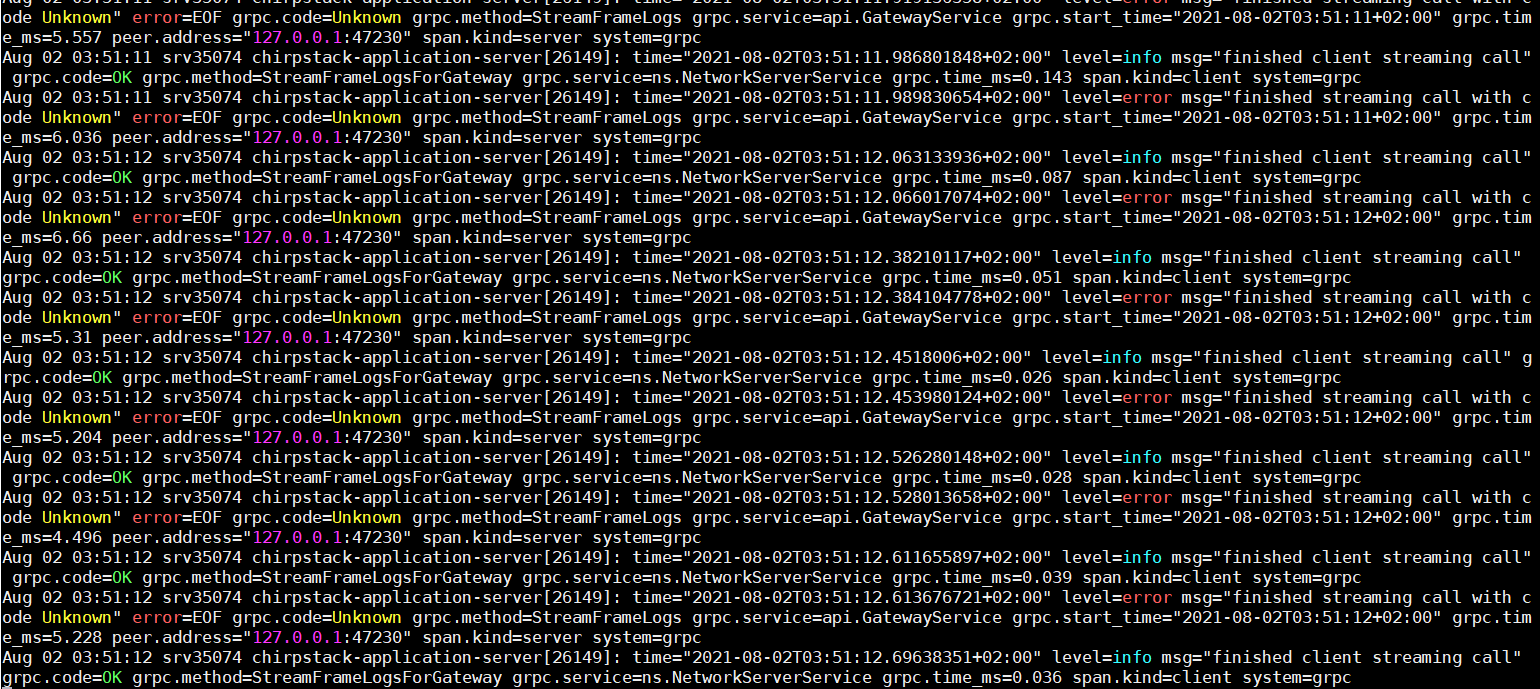
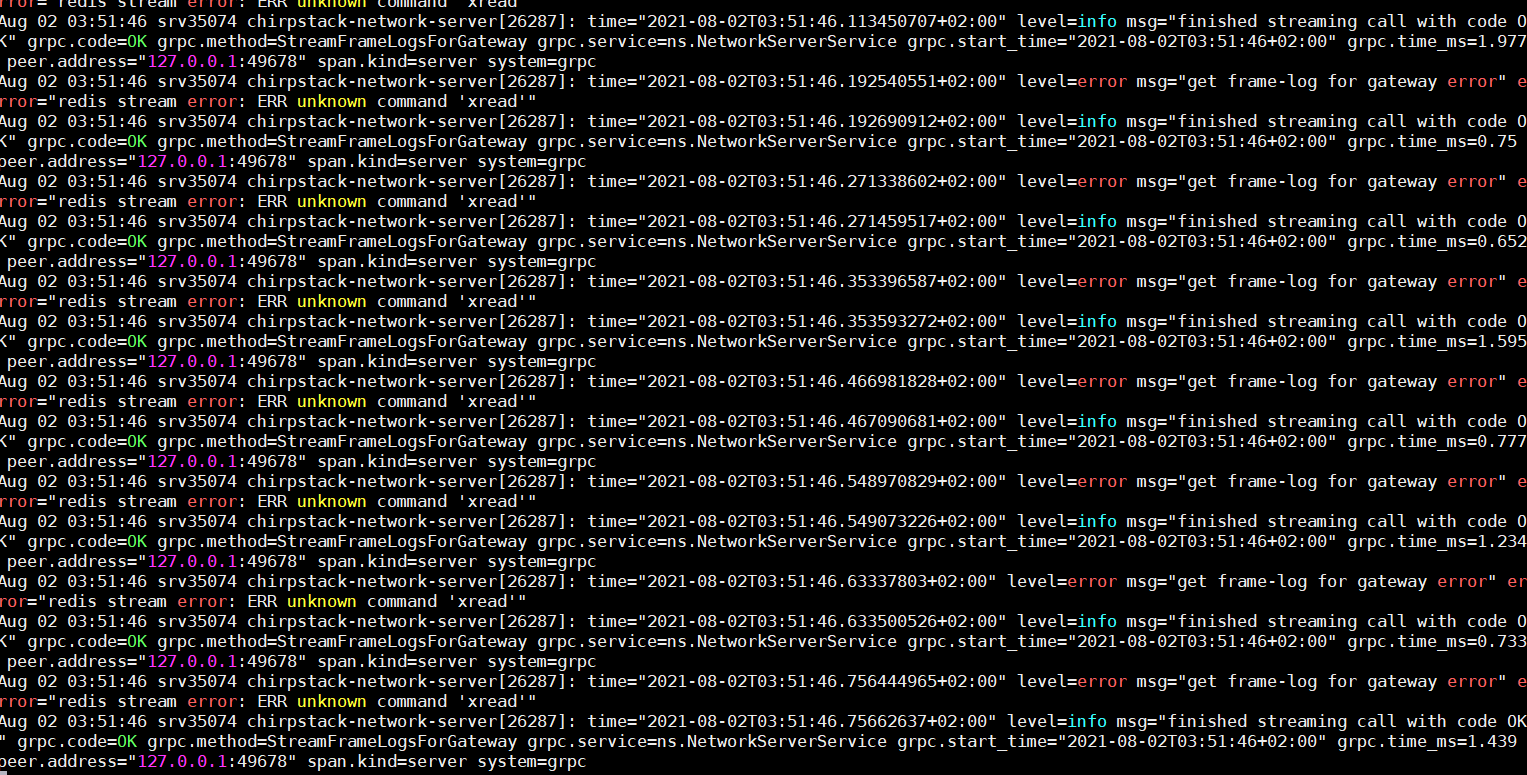
the redis-server and redis-cli version is 4.0.9 and the ubuntu 18.04.5 LTS. I didn’t have this problem in another machine with the same versions.
I have changed external port to 8090, networkserver port to 8200, application server public and internal api port to 8100 and joinserver port to 8003.
below is application server log:
I’m new to using ChirpStack, so I have the same problem that @msadeghz about Redis 4.0.9. I know that the solution is to update Redis to 6.2.5 but I don’t know how to do it, I don’t know what’s are the correct ssh commands.
NOTE: I’m using Ubuntu 18.0.4 and I installed ChirpStack using the Quickstart Ubuntu Guide.
Same issue here. Looked all over in terms of upgrading Redis, but no mention on the upgrade process.
Ubuntu 18.0.4
Latest Chirpstack updates.
Don’t want to cause issues on a working server.
I really could use a help file on upgrading Redis.
It took me a lot of digging to realize that maybe it’s so unintuitive (aka “hard”) to upgrade redis because they made it so trivial! Reading HERE:
Upgrading nodes in a Redis Cluster
Upgrading replica nodes is easy since you just need to stop the node and restart it with an updated version of Redis. If there are clients scaling reads using replica nodes, they should be able to reconnect to a different replica if a given one is not available.
Upgrading masters is a bit more complex, and the suggested procedure is:
Use CLUSTER FAILOVER to trigger a manual failover of the master to one of its replicas. (See the Manual failover section in this document.)
Wait for the master to turn into a replica.
Finally upgrade the node as you do for replicas.
If you want the master to be the node you just upgraded, trigger a new manual failover in order to turn back the upgraded node into a master.
Following this procedure you should upgrade one node after the other until all the nodes are upgraded.
Thanks! I am on an AWS EC2 instance and needed to upgrade anyway, so I upgraded from LTS18.04 to LTS20.04 and that took care of the upgrade for me. I then went on to LTS22.04 and all is well. An oddity is that Grafana 9.1.2 doesn’t seem to work, so staying on 9.1.1 for now. Thanks for the help. Nice to have the instances as they make it extremely easy to backup and restore quickly so I was able to snapshot a testing instance before applying the upgrade to the working server. Thanks again!